Week 7 [Fri, Sep 22nd] - Topics
Guidance for the item(s) below:
Previously, you learned a number of techniques for specifying requirements. There's one more left, which we'll cover this week.
Can explain use cases
Use case: A description of a set of sequences of actions, including variants, that a system performs to yield an observable result of value to an actor [ 📖 : ].
A use case describes an interaction between the user and the system for a specific functionality of the system.
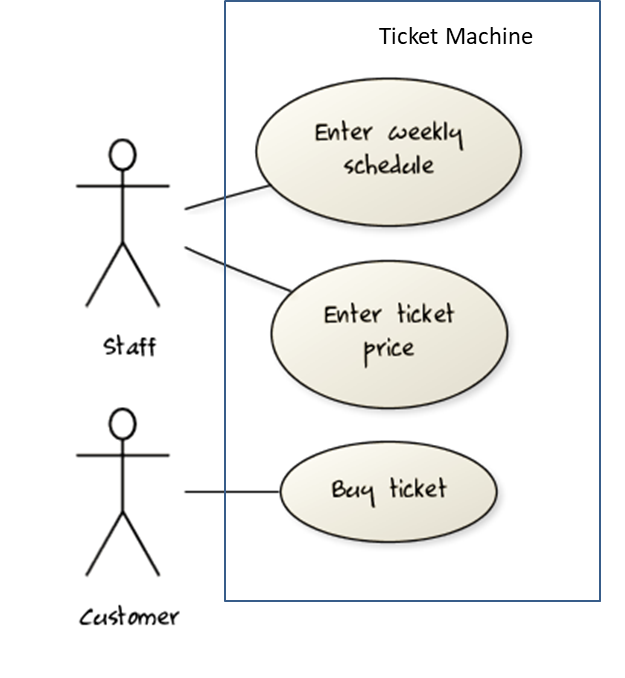
UML includes a diagram type called use case diagrams that can illustrate use cases of a system visually, providing a visual ‘table of contents’ of the use cases of a system.
In the example on the right, note how use cases are shown as ovals and user roles relevant to each use case are shown as stick figures connected to the corresponding ovals.
Use cases capture the functional requirements of a system.
Can specify details of a use case in a structured format
Writing use case steps
The main body of the use case is a sequence of steps that describes the interaction between the system and the actors. Each step is given as a simple statement describing who does what.
An example of the main body of a use case.
- Student requests to upload file
- LMS requests for the file location
- Student specifies the file location
- LMS uploads the file
A use case describes only the externally visible behavior, not internal details, of a system i.e. should minimize details that are not part of the interaction between the user and the system.
This example use case step refers to behaviors not externally visible.
- LMS saves the file into the cache and indicates success.
A step gives the intention of the actor (not the mechanics). That means UI details are usually omitted. The idea is to leave as much flexibility to the UI designer as possible. That is, the use case specification should be as general as possible (less specific) about the UI.
The first example below is not a good use case step because it contains UI-specific details. The second one is better because it omits UI-specific details.
Bad : User right-clicks the text box and chooses ‘clear’
Good : User clears the input
A use case description can show loops too.
An example of how you can show a loop:
Software System: SquareGame
Use case: - Play a Game
Actors: Player (multiple players)
MSS:
- A Player starts the game.
- SquareGame asks for player names.
- Each Player enters his own name.
- SquareGame shows the order of play.
- SquareGame prompts for the current Player to throw a die.
- Current Player adjusts the throw speed.
- Current Player triggers the die throw.
- SquareGame shows the face value of the die.
- SquareGame moves the Player's piece accordingly.
Steps 5-9 are repeated for each Player, and for as many rounds as required until a Player reaches the 100th square. - SquareGame shows the Winner.
Use case ends.
The Main Success Scenario (MSS) describes the most straightforward interaction for a given use case, which assumes that nothing goes wrong. This is also called the Basic Course of Action or the Main Flow of Events of a use case.
Note how the MSS in the example below assumes that all entered details are correct and ignores problems such as timeouts, network outages etc. For example, the MSS does not tell us what happens if the user enters incorrect data.
System: Online Banking System (OBS)
Use case: UC23 - Transfer Money
Actor: User
MSS:
- User chooses to transfer money.
- OBS requests for details of the transfer.
- User enters the requested details.
- OBS requests for confirmation.
- OBS transfers the money and displays the new account balance.
Use case ends.
Extensions are "add-on"s to the MSS that describe exceptional/alternative flow of events. They describe variations of the scenario that can happen if certain things are not as expected by the MSS. Extensions appear below the MSS.
This example adds some extensions to the use case in the previous example.
System: Online Banking System (OBS) Use case: UC23 - Transfer Money Actor: User MSS: 1. User chooses to transfer money. 2. OBS requests for details of the transfer. 3. User enters the requested details. 4. OBS requests for confirmation. 5. User confirms. 6. OBS transfers the money and displays the new account balance. Use case ends.
Extensions:
3a. OBS detects an error in the entered data.
3a1. OBS requests for the correct data.
3a2. User enters new data.
Steps 3a1-3a2 are repeated until the data entered are correct.
Use case resumes from step 4.
3b. User requests to effect the transfer in a future date.
3b1. OBS requests for confirmation.
3b2. User confirms future transfer.
Use case ends.
*a. At any time, User chooses to cancel the transfer.
*a1. OBS requests to confirm the cancellation.
*a2. User confirms the cancellation.
Use case ends.
*b. At any time, 120 seconds lapse without any input from the User.
*b1. OBS cancels the transfer.
*b2. OBS informs the User of the cancellation.
Use case ends.
Note that the numbering style is not a universal rule but a widely used convention. Based on that convention,
- either of the extensions marked
3a.and3b.can happen just after step3of the MSS. - the extension marked as
*a.can happen at any step (hence, the*).
When separating extensions from the MSS, keep in mind that the MSS should be self-contained. That is, the MSS should give us a complete usage scenario.
Also note that it is not useful to mention events such as power failures or system crashes as extensions because the system cannot function beyond such catastrophic failures.
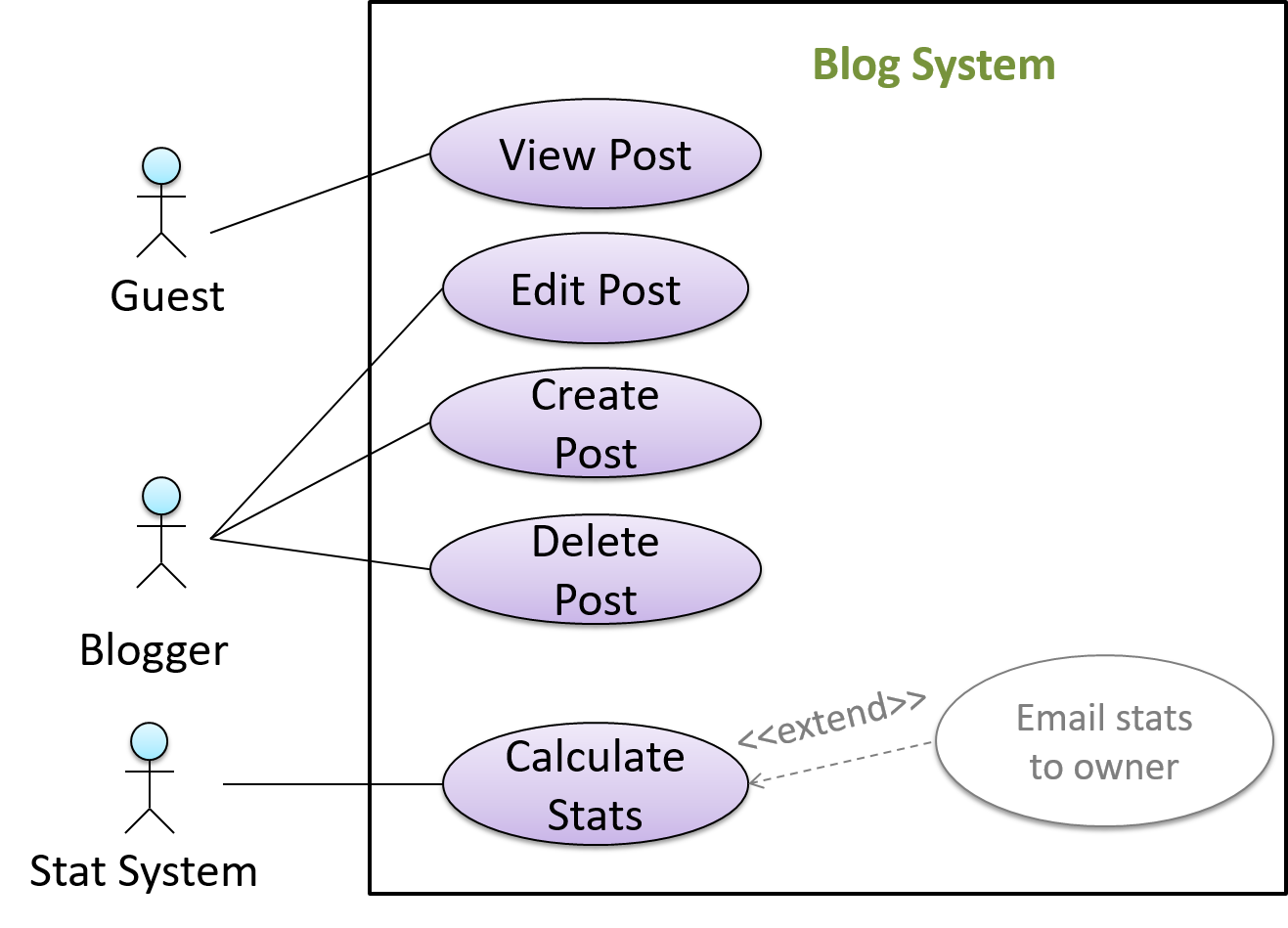
In use case diagrams you can use the <<extend>> arrows to show extensions. Note the direction of the arrow is from the extension to the use case it extends and the arrow uses a dashed line.
A use case can include another use case. Underlined text is used to show an inclusion of a use case.
This use case includes two other use cases, one in step 1 and one in step 2.
- Software System: LearnSys
- Use case: UC01 - Conduct Survey
- Actors: Staff, Student
- MSS:
- Staff creates the survey (UC44).
- Student completes the survey (UC50).
- Staff views the survey results.
Use case ends.
Inclusions are useful,
- when you don't want to clutter a use case with too many low-level steps.
- when a set of steps is repeated in multiple use cases.
You use a dotted arrow and an <<include>> annotation to show use case inclusions in a use case diagram. Note how the arrow direction is different from the <<extend>> arrows.
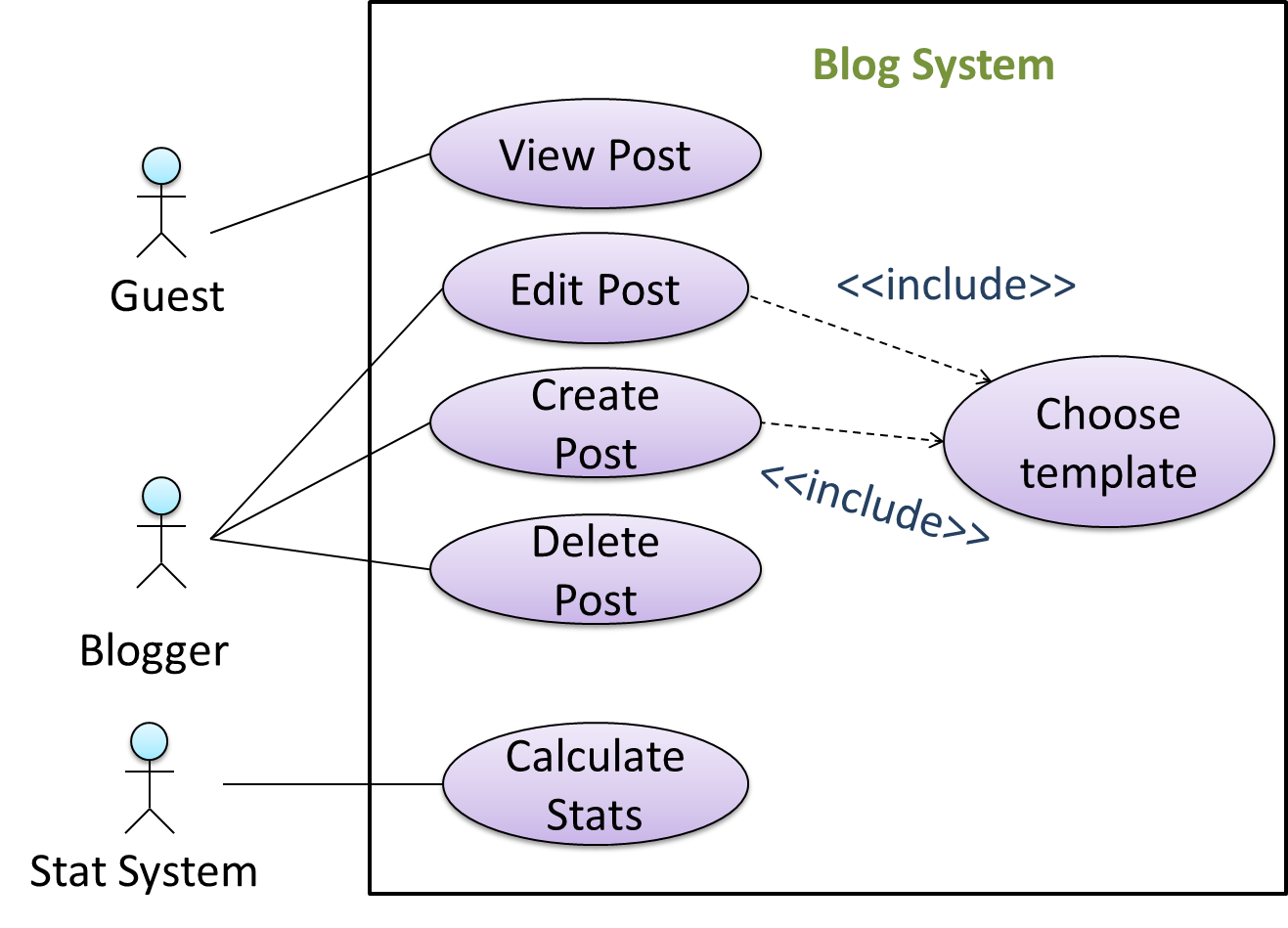
Preconditions specify the specific state you expect the system to be in before the use case starts.
Software System: Online Banking System
Use case: UC23 - Transfer Money
Actor: User
Preconditions: User is logged in
MSS:
- User chooses to transfer money.
- OBS requests for details for the transfer.
...
Guarantees specify what the use case promises to give us at the end of its operation.
Software System: Online Banking System
Use case: UC23 - Transfer Money
Actor: User
Preconditions: User is logged in.
Guarantees:
- Money will be deducted from the source account only if the transfer to the destination account is successful.
- The transfer will not result in the account balance going below the minimum balance required.
MSS:
- User chooses to transfer money.
- OBS requests for details for the transfer.
...
Can optimize the use of use cases
You can use actor generalization in use case diagrams using a symbol similar to that of UML notation for inheritance.
In this example, actor Blogger can do all the use cases the actor Guest can do, as a result of the actor generalization relationship given in the diagram.
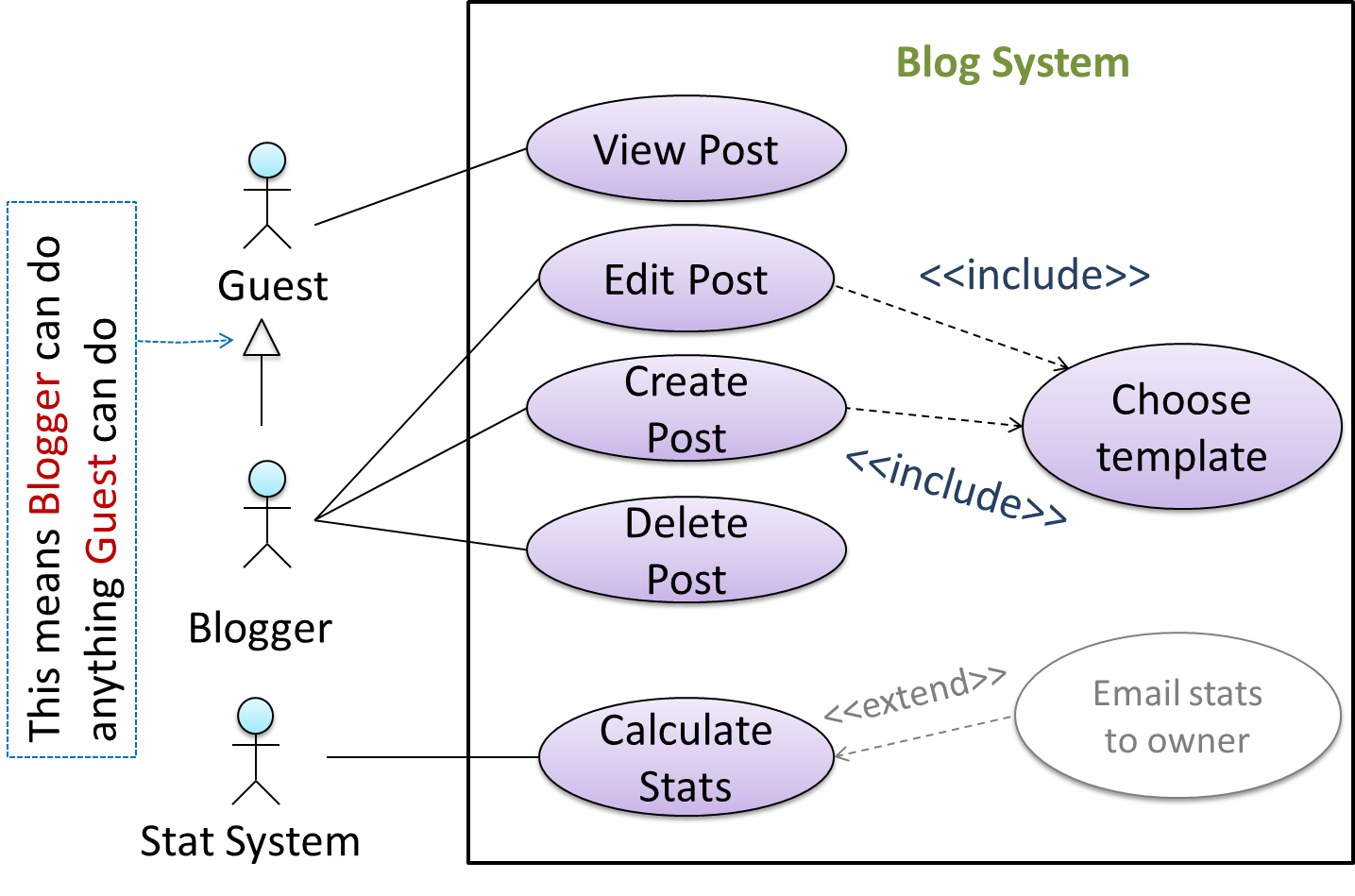
Do not over-complicate use case diagrams by trying to include everything possible. A use case diagram is a brief summary of the use cases that is used as a starting point. Details of the use cases can be given in the use case descriptions.
Some include ‘System’ as an actor to indicate that something is done by the system itself without being initiated by a user or an external system.
The diagram below can be used to indicate that the system generates daily reports at midnight.
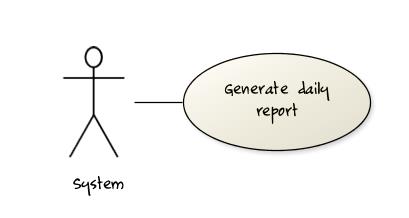
However, others argue that only use cases providing value to an external user/system should be shown in the use case diagram. For example, they argue that view daily report should be the use case and generate daily report is not to be shown in the use case diagram because it is simply something the system has to do to support the view daily report use case.
You are recommended to follow the latter view (i.e. not to use System as a user). Limit use cases for modeling behaviors that involve an external actor.
UML is not very specific about the text contents of a use case. Hence, there are many styles for writing use cases. For example, the steps can be written as a continuous paragraph.
Use cases should be easy to read. Note that there is no strict rule about writing all details of all steps or a need to use all the elements of a use case.
There are some advantages of documenting system requirements as use cases:
- Because they use a simple notation and plain English descriptions, they are easy for users to understand and give feedback.
- They decouple user intention from mechanism (note that use cases should not include UI-specific details), allowing the system designers more freedom to optimize how a functionality is provided to a user.
- Identifying all possible extensions encourages us to consider all situations that a software product might face during its operation.
- Separating typical scenarios from special cases encourages us to optimize the typical scenarios.
One of the main disadvantages of use cases is that they are not good for capturing requirements that do not involve a user interacting with the system. Hence, they should not be used as the sole means to specify requirements.
Follow up notes for the item(s) above:
Now that you know all the different ways of specifying requirements, here is an example that shows how all techniques of specifying requirements can work together:
Guidance for the item(s) below:
In the tP, you start with a code base that already has a certain design. What if there is no such design for you to start with? The next few topics look at how one can come up with such a design yourself.
Guidance for the item(s) below:
As you do projects, you'll have to make design decisions e.g., decide between multiple design alternatives. Let us learn three fundamental design concepts that you can use in those decisions.
It is extremely important for you to know these three because they are like the DNA of every higher-level design concept.
Abstraction
Coupling
Can explain coupling
Coupling is a measure of the degree of dependence between components, classes, methods, etc. Low coupling indicates that a component is less dependent on other components. High coupling (aka tight coupling or strong coupling) is discouraged due to the following disadvantages:
- Maintenance is harder because a change in one module could cause changes in other modules coupled to it (i.e. a ripple effect).
- Integration is harder because multiple components coupled with each other have to be integrated at the same time.
- Testing and reuse of the module is harder due to its dependence on other modules.
In the example below, design A appears to have more coupling between the components than design B.
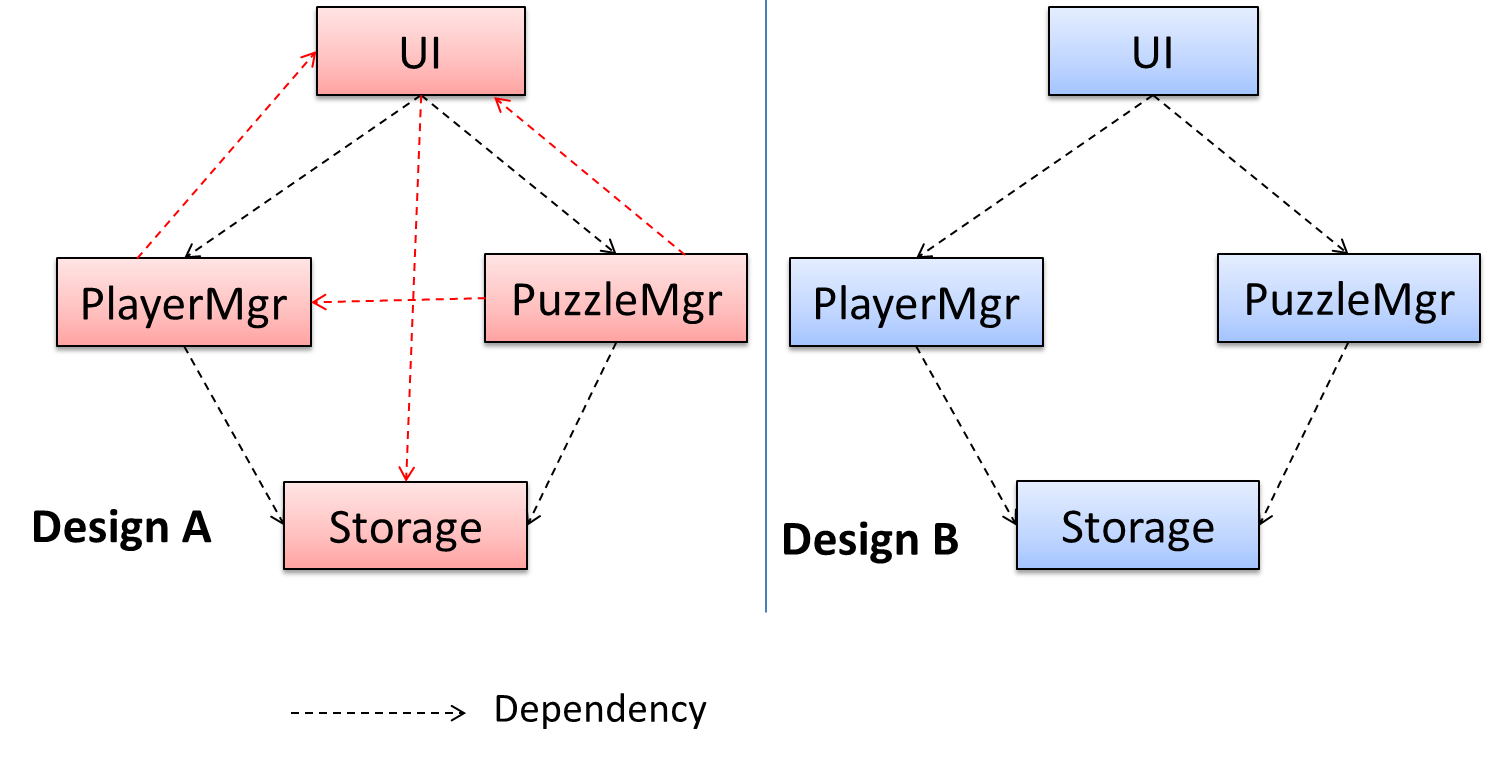
Cohesion
Guidance for the item(s) below:
In case you are the type who want to become a 'power user' of IDEs (it's not a bad idea, given the IDE is like the primary tool of a software engineer), given below are some more things you can do with IDEs.
Guidance for the item(s) below:
As you start adding new code to the tP, let's also become aware of various approaches in integrating new code to a product.
Guidance for the item(s) below:
Coordinating a team project is not easy. Given below are some very basic tools and techniques that are often used in planning, scheduling, and tracking projects.
Can explain buffers
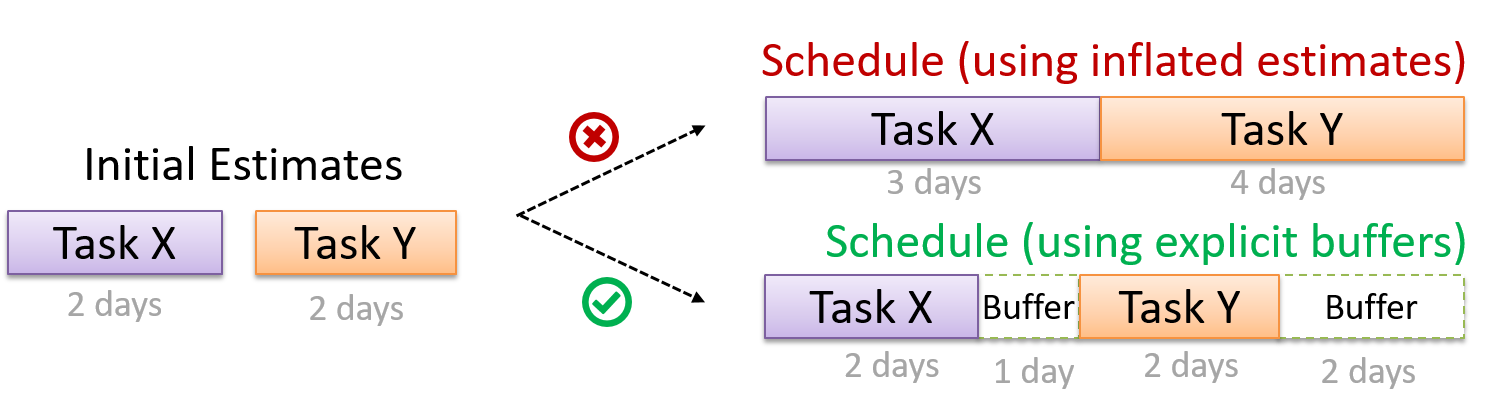
A buffer is time set aside to absorb any unforeseen delays. It is very important to include buffers in a software project schedule because effort/time estimations for software development are notoriously hard. However, do not inflate task estimates to create hidden buffers; have explicit buffers instead. Reason: With explicit buffers, it is easier to detect incorrect effort estimates which can serve as feedback to improve future effort estimates.
Can explain issue trackers
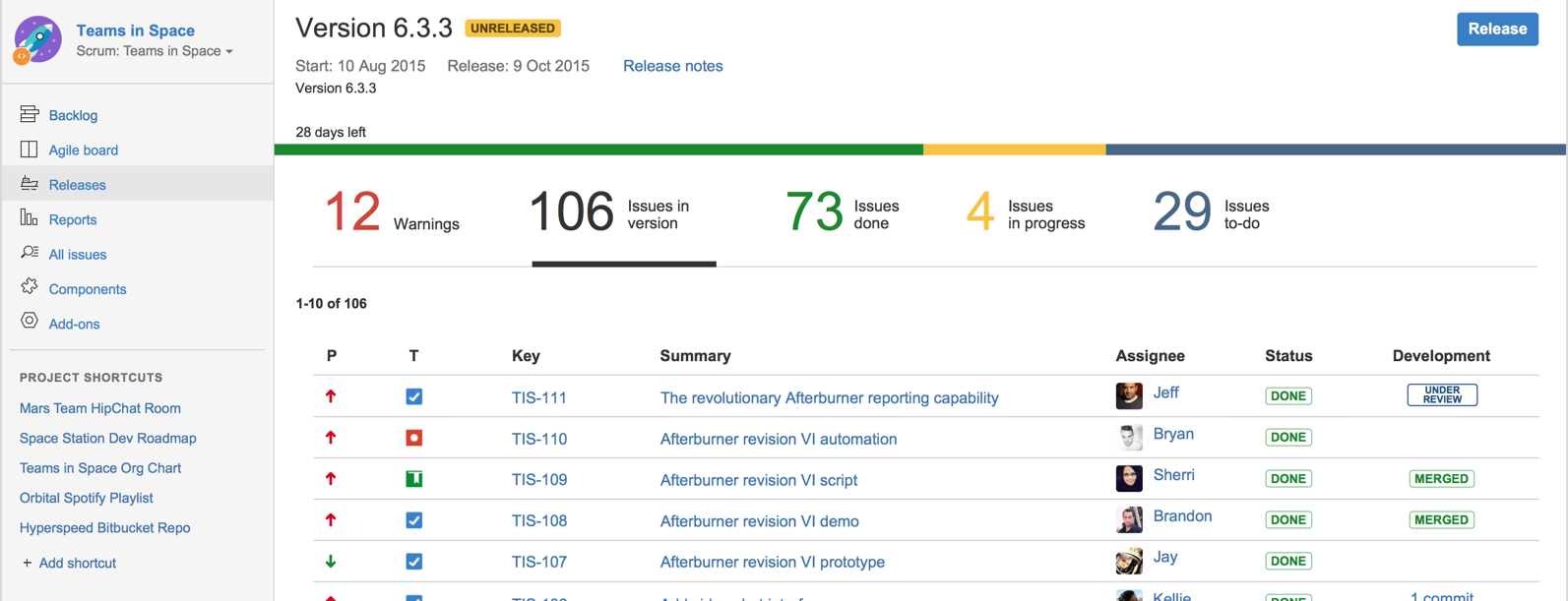
Keeping track of project tasks (who is doing what, which tasks are ongoing, which tasks are done etc.) is an essential part of project management. In small projects, it may be possible to keep track of tasks using simple tools such as online spreadsheets or general-purpose/light-weight task tracking tools such as Trello. Bigger projects need more sophisticated task tracking tools.
Issue trackers (sometimes called bug trackers) are commonly used to track task assignment and progress. Most online project management software such as GitHub, SourceForge, and BitBucket come with an integrated issue tracker.
A screenshot from the Jira Issue tracker software (Jira is part of the BitBucket project management tool suite):
Can explain Gantt charts
A Gantt chart is a 2-D bar-chart, drawn as time vs tasks (represented by horizontal bars).
A sample Gantt chart:
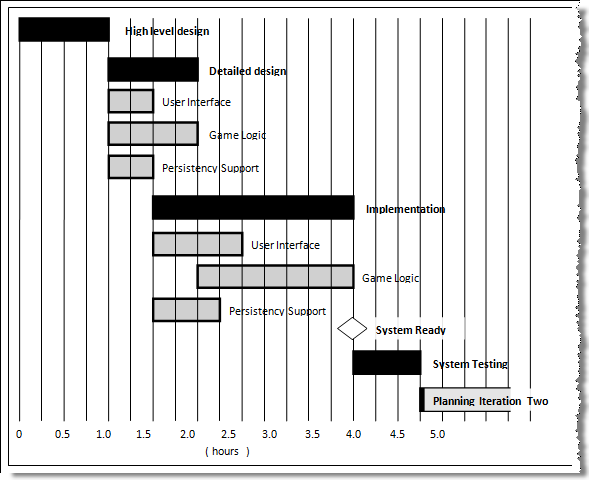
In a Gantt chart, a solid bar represents the main task, which is generally composed of a number of subtasks, shown as grey bars. The diamond shape indicates an important deadline/deliverable/milestone.
Can explain common team structures
Given below are three commonly used team structures in software development. Irrespective of the team structure, it is a good practice to assign roles and responsibilities to different team members so that someone is clearly in charge of each aspect of the project. In comparison, the ‘everybody is responsible for everything’ approach can result in more chaos and hence slower progress.
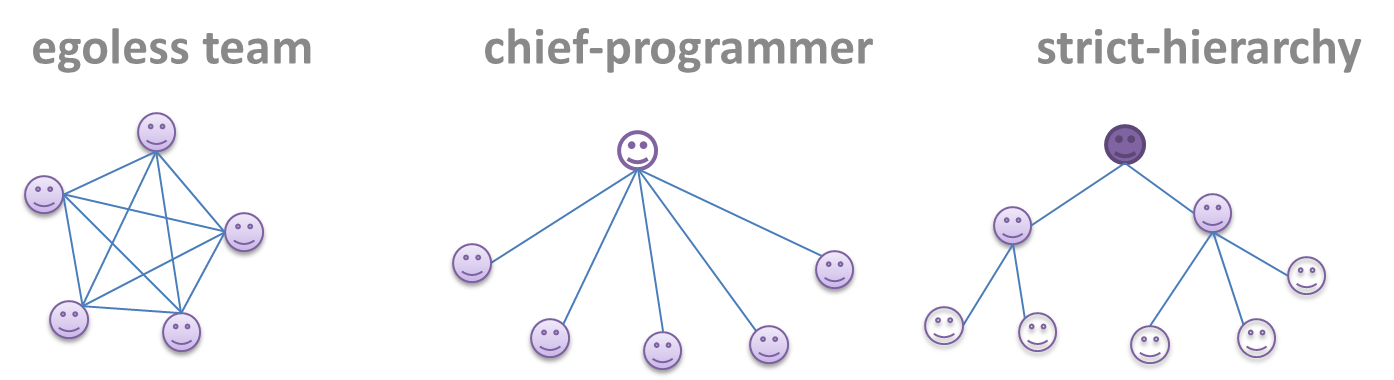
Egoless team
In this structure, every team member is equal in terms of responsibility and accountability. When any decision is required, consensus must be reached. This team structure is also known as a democratic team structure. This team structure usually finds a good solution to a relatively hard problem as all team members contribute ideas.
However, the democratic nature of the team structure bears a higher risk of falling apart due to the absence of an authority figure to manage the team and resolve conflicts.
Chief programmer team
Frederick Brooks proposed that software engineers learn from the medical surgical team in an operating room. In such a team, there is always a chief surgeon, assisted by experts in other areas. Similarly, in a chief programmer team structure, there is a single authoritative figure, the chief programmer. Major decisions, e.g. system architecture, are made solely by him/her and obeyed by all other team members. The chief programmer directs and coordinates the effort of other team members. When necessary, the chief will be assisted by domain specialists e.g. business specialists, database experts, network technology experts, etc. This allows individual group members to concentrate solely on the areas in which they have sound knowledge and expertise.
The success of such a team structure relies heavily on the chief programmer. Not only must he/she be a superb technical hand, he/she also needs good managerial skills. Under a suitably qualified leader, such a team structure is known to produce successful work.
Strict hierarchy team
At the opposite extreme of an egoless team, a strict hierarchy team has a strictly defined organization among the team members, reminiscent of the military or a bureaucratic government. Each team member only works on his/her assigned tasks and reports to a single “boss”.
In a large, resource-intensive, complex project, this could be a good team structure to reduce communication overhead.
Guidance for the item(s) below:
Continuing on the same theme, given below are more practices used in managing projects, particularly related to the revision control aspect.
Can explain forking workflow
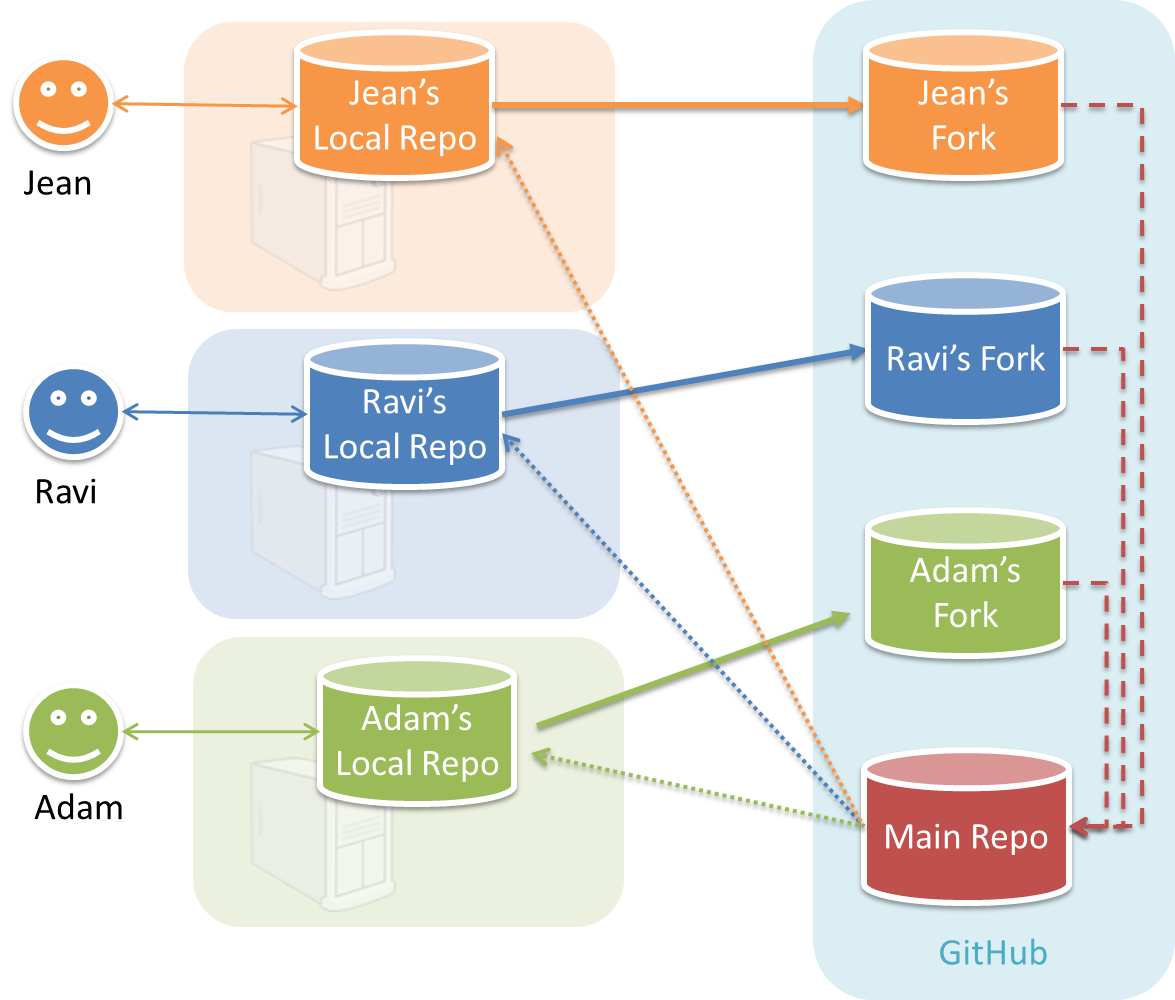
In the forking workflow, the 'official' version of the software is kept in a remote repo designated as the 'main repo'. All team members fork the main repo and create pull requests from their fork to the main repo.
To illustrate how the workflow goes, let’s assume Jean wants to fix a bug in the code. Here are the steps:
- Jean creates a separate branch in her local repo and fixes the bug in that branch.
Common mistake: Doing the proposed changes in themasterbranch -- if Jean does that, she will not be able to have more than one PR open at any time because any changes to themasterbranch will be reflected in all open PRs. - Jean pushes the branch to her fork.
- Jean creates a pull request from that branch in her fork to the main repo.
- Other members review Jean’s pull request.
- If reviewers suggested any changes, Jean updates the PR accordingly.
- When reviewers are satisfied with the PR, one of the members (usually the team lead or a designated 'maintainer' of the main repo) merges the PR, which brings Jean’s code to the main repo.
- Other members, realizing there is new code in the upstream repo, sync their forks with the new upstream repo (i.e. the main repo). This is done by pulling the new code to their own local repo and pushing the updated code to their own fork. If there are unmerged branches in the local repo, they can be updated too e.g., by merging the new
masterbranch to each of them.
Possible mistake: Creating another 'reverse' PR from the team repo to the team member's fork to sync the member's fork with the merged code. PRs are meant to go from downstream repos to upstream repos, not in the other direction.
One main benefit of this workflow is that it does not require most contributors to have write permissions to the main repository. Only those who are merging PRs need write permissions. The main drawback of this workflow is the extra overhead of sending everything through forks.
Can explain DRCS vs CRCS
RCS can be done in two ways: the centralized way and the distributed way.
Centralized RCS (CRCS for short) uses a central remote repo that is shared by the team. Team members download (‘pull’) and upload (‘push’) changes between their own local repositories and the central repository. Older RCS tools such as CVS and SVN support only this model. Note that these older RCS do not support the notion of a local repo either. Instead, they force users to do all the versioning with the remote repo.
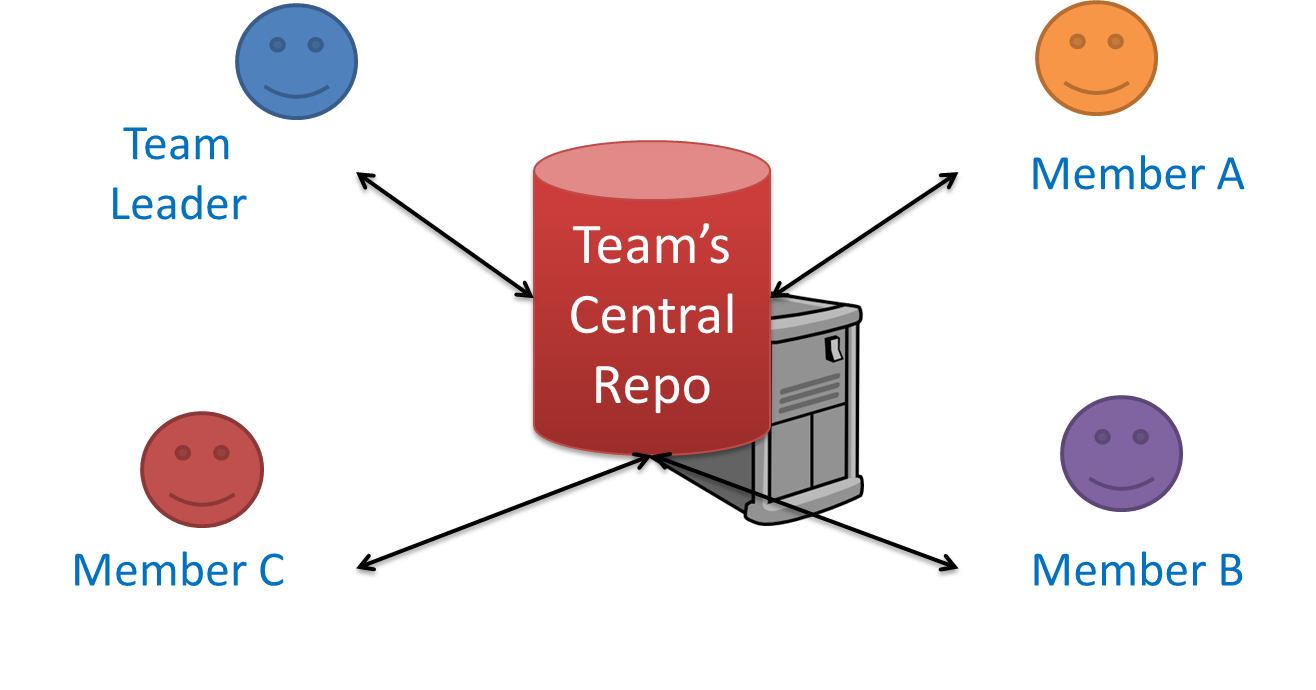
The centralized RCS approach without any local repos (e.g., CVS, SVN)
Distributed RCS (DRCS for short, also known as Decentralized RCS) allows multiple remote repos and pulling and pushing can be done among them in arbitrary ways. The workflow can vary differently from team to team. For example, every team member can have his/her own remote repository in addition to their own local repository, as shown in the diagram below. Git and Mercurial are some prominent RCS tools that support the distributed approach.
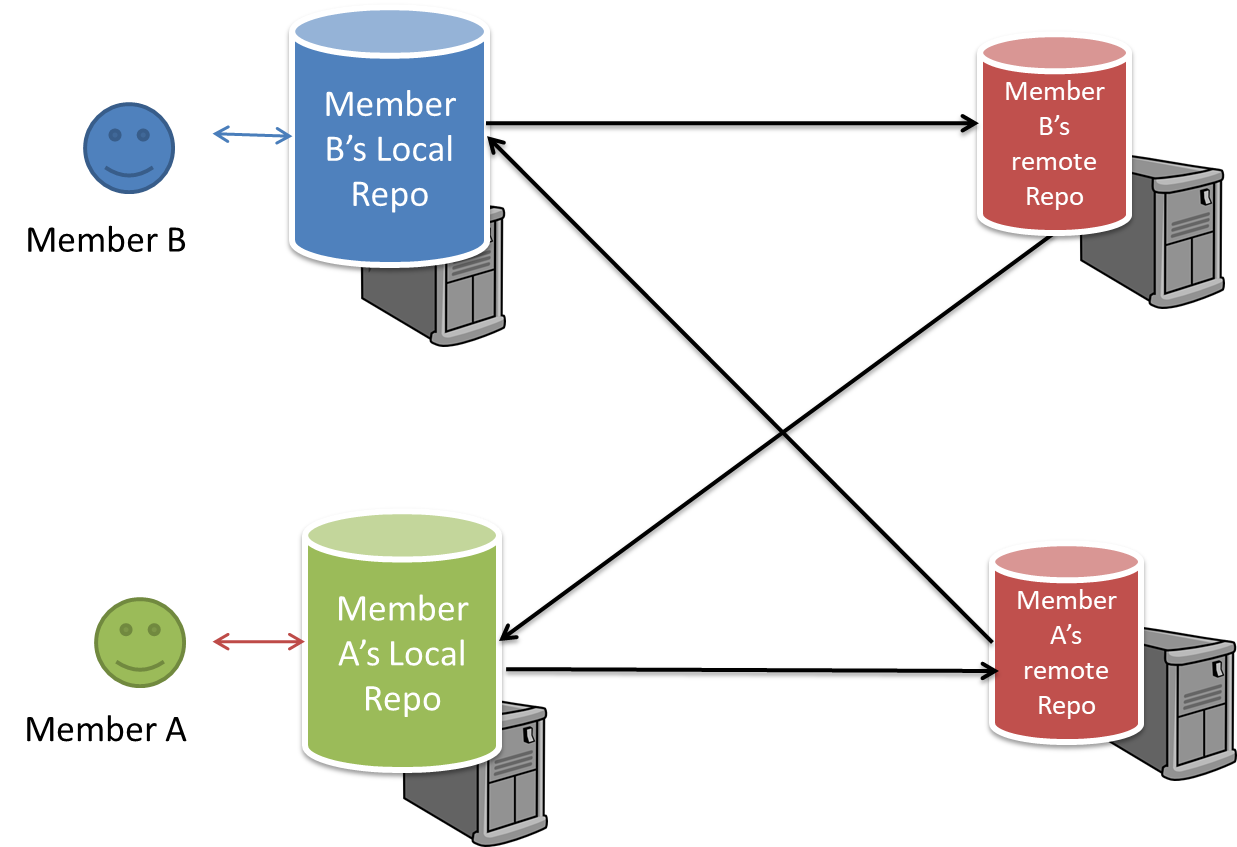
The decentralized RCS approach